How well do large-language models understand plant biology?
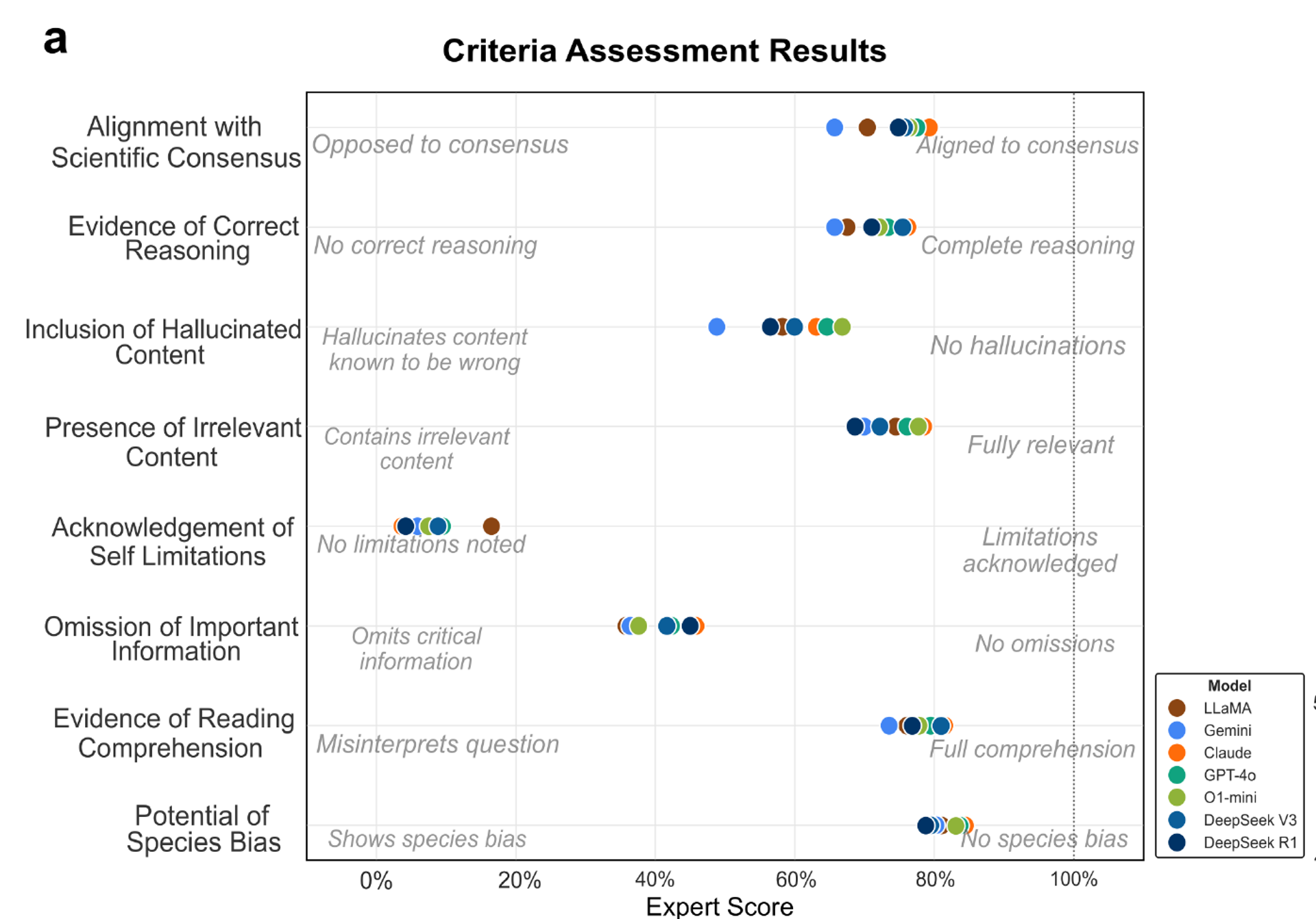 This very interesting preprint by Fernández Burda et al. investigates how well large-language models (LLMs, such as ChatGPT) are able to correctly answer questions about plant molecular biology. The article is a huge group effort that engaged the help of over 100 plant scientists to develop MoBioPlant (https://huggingface.co/datasets/manufernandezbur/MoBiPlant) as a resource. The group created a database of hundreds of questions (multiple choice and open-ended) that they posed to LLMs, and scored the different tools for their accuracy. The results are not bad, but also raise concerns about the widespread use of LLMs. Although the LLMs scored better than random on multiple choice questions, selecting the correct answer 75% of the time, they also showed their limitations. The paper presents plenty of evidence for the types of hallucinations that LLMs have been charged with, in which they present made-up facts as data, and cite non-existent articles. Not surprisingly, they show a bias towards more highly cited papers, reflecting their frequency in the models they were trained on. Whether you are a student or instructor, author or reviewer, you should remember, your critical thinking skills are better than those of a LLM. (Summary by @PlantTeaching.bsyk.social) bioRxiv https://www.biorxiv.org/content/10.1101/2025.08.31.672925v1
This very interesting preprint by Fernández Burda et al. investigates how well large-language models (LLMs, such as ChatGPT) are able to correctly answer questions about plant molecular biology. The article is a huge group effort that engaged the help of over 100 plant scientists to develop MoBioPlant (https://huggingface.co/datasets/manufernandezbur/MoBiPlant) as a resource. The group created a database of hundreds of questions (multiple choice and open-ended) that they posed to LLMs, and scored the different tools for their accuracy. The results are not bad, but also raise concerns about the widespread use of LLMs. Although the LLMs scored better than random on multiple choice questions, selecting the correct answer 75% of the time, they also showed their limitations. The paper presents plenty of evidence for the types of hallucinations that LLMs have been charged with, in which they present made-up facts as data, and cite non-existent articles. Not surprisingly, they show a bias towards more highly cited papers, reflecting their frequency in the models they were trained on. Whether you are a student or instructor, author or reviewer, you should remember, your critical thinking skills are better than those of a LLM. (Summary by @PlantTeaching.bsyk.social) bioRxiv https://www.biorxiv.org/content/10.1101/2025.08.31.672925v1


